Building Data Infrastructure for Biology
ALSO: Featuring Omics Solution Providers Market Map, from Multiomics to Spatial Biology
Hi! I am Andrii Buvailo, and this is my weekly newsletter, ‘Where Tech Meets Bio,’ where I talk about technologies, breakthroughs, and great companies moving the biopharma industry forward.
If you've received it, then you either subscribed or someone forwarded it to you. If the latter is the case, subscribe by pressing this button:
This newsletter is sponsored by LatchBio, a provider of next-generation cloud infrastructure for biology research.
Hundreds of biotechs use Latch to make data analysis faster, cheaper, more accessible, and instantly accelerate their R&D milestones.

To learn more about Latch’s complete production solution for kit, assay, and solution providers, sign up for a free 7-day trial here.
Now, let’s get to this week’s topic!
Enabling Data Infrastructure for Biology
The advent of artificial intelligence (AI) in drug discovery and biotech is remarkable. But the foundational premise for any major success in this area is high-quality biological and medical data, properly managed, curated, and accessible to various parties involved in the R&D work.
That's why I believe we should talk a bit less about cutting edge AI algorithms, and more about the following categories of companies:
companies building ways to get novel data (analytical tools and instruments, scientific methods, research kit providers, robotic labs as a service, etc)
data providers (biobanks, EHRs, etc)
companies helping manage and analyze big biological data in machine learning-friendly ways
So, below is a nuanced take on various aspects of building a strong data foundation for biology research, especially relevant to assay, kit, and solution providers within the life sciences industry.
As biology advances exponentially, new multi-omic technologies to read, write, and edit cells (genome, proteome, metabolome, or epigenome) emerge every week, rapidly increasing the level of complexity. Techniques that would have made the cover of Nature Biotech ten years ago are now standard in experimental protocols. Skills that once required an entire PhD and postdoc to master are now routinely expected from a first-year research associate.
How are we supposed to keep exploring the farthest boundaries of biological possibilities if even the most basic discoveries depend on such complex and rapidly changing multi-omic technologies?
Enter biological solutions providers. They play a crucial role in transforming cutting-edge biology into accessible solutions by abstracting these complex but essential tools into services, kits, or instruments.
The Struggle for Meaningful Results
Getting raw assay data into a state that is easily accessible and understandable for customers is often impossible.
As kits push the scale and resolution at which we are able to interrogate biology (more cells, more reads, etc.), downstream analysis suffers from uniquely large computing and storage pain.
Take the example of AtlasXOmics, which offers a comprehensive solution to map the spatial epigenome at a cellular resolution.
Despite AtlasXOmics’ novel DBiT-seq technology, customers were initially unable to grasp the biological insights they would derive from these assays:
Each kit can produce terabytes worth of raw data for kit providers, making it challenging to share with customers.
The bioinformatics pipelines required to process these datasets require parallelization of multiple computers and several hours to finish. They often point customers to an existing GitHub repository requiring advanced bioinformatics expertise to self-serve. There’s no guarantee that customers can run the pipeline successfully and achieve the final insight themselves.
Once the data has been processed, it is often delivered as text files or CSVs that are not readily digestible by scientific teams. HTML reports or RShiny applications and dashboards are viable workarounds, but they often require internal efforts to customize and deliver on a customer-by-customer basis.
These computational challenges are not unique to AtlasXOmics. Many kit and assay providers experience a frustrating disconnect because customers purchase the kit not solely for the kit but for the scientific questions it enables them to explore.
Customer Journey Suffers
Due to the compute-intensive nature of high-throughput sequencing data, the journey from assay to insights can be long and arduous for customers, often spanning weeks or even months.
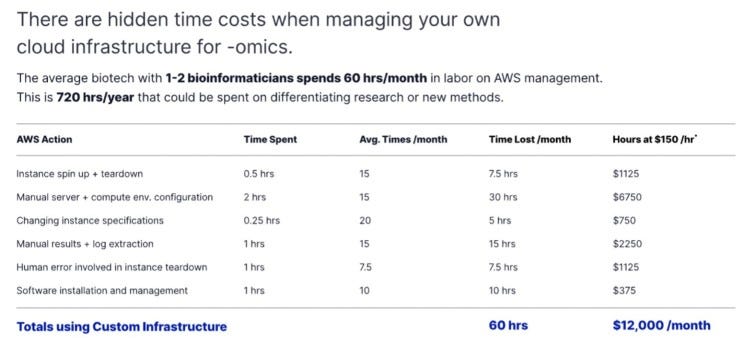
Many kit providers are considering building an in-house, customer-facing bioinformatics solution. However, they also worry about the opportunity cost & time sunk into making such a solution production-ready, not to mention the resources required to maintain such a solution long-term.
The Status Quo
As a result, many shy away from a differentiated offering with dynamic reports & visualizations, sticking with the tried-and-true status quo: no complementary analyses at all (reducing potential revenue) or sending static reports and zipped data folders over email (reducing insight into whether customers find these outputs useful).
There must be a more straightforward way to ensure every customer experiences that magical "Aha" moment right from day one, immediately after using your kit.
LatchBio has built close partnerships with CROs and kit manufacturers across markets to design a white-labeled, purpose-built bioinformatics platform to deliver analyses to customers quickly.
Latch is the First Bioinformatics Delivery Platform Focused on the Assay, Kit, and Solutions Provider Market
Latch offers bioinformatics delivery to assay, kit, and solution providers, empowering them to deliver a delightful, white-labeled web portal to their customers on day 1.
How it works:
From a kit/assay/solution provider point-of-view:
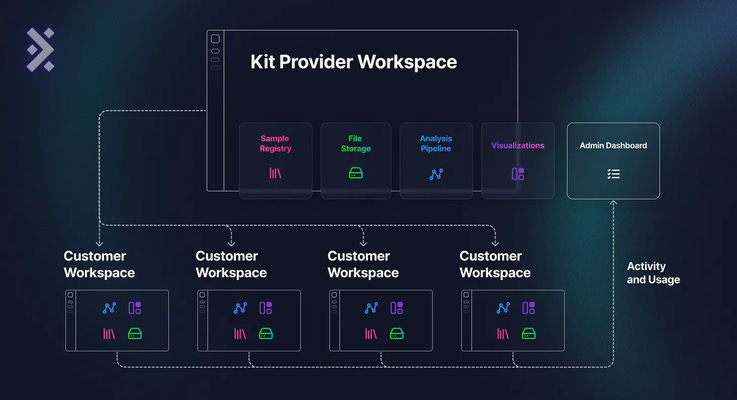
A kit provider can log into the Latch platform and create an internal workspace for their team. With a Latch workspace, they can:
Mount data from various sources (local computer, BaseSpace, AWS, Google Cloud), and have a central, intuitive file system in Latch Data.
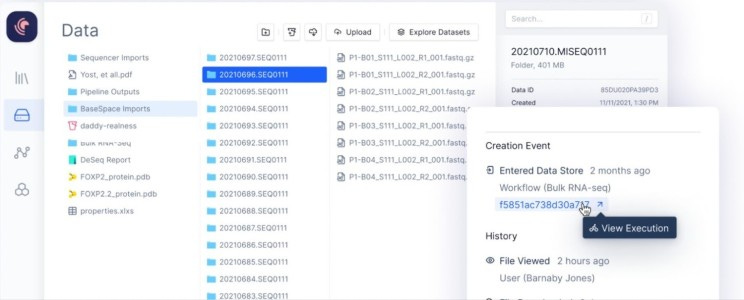
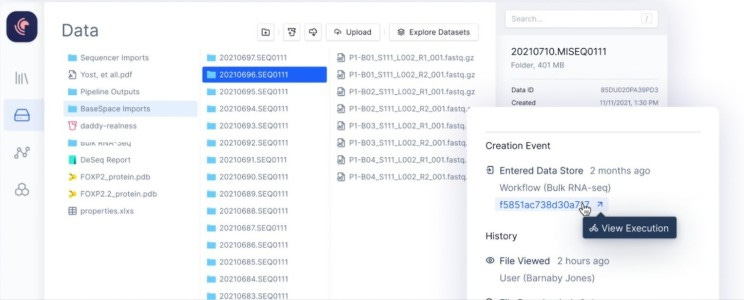
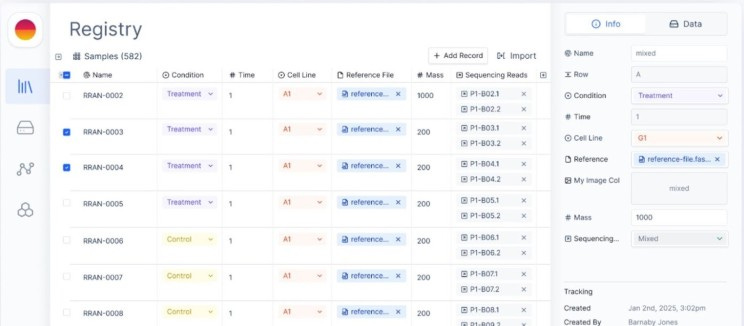
Organize samples with contextual metadata in the Latch Registry.
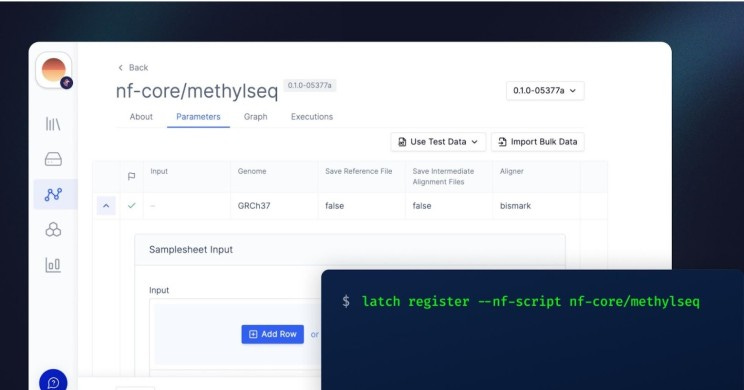
Publish existing Nextflow and Snakemake to their private workspace on Latch while automatically receiving user-friendly, no-code GUI and scalable infrastructure using the Latch SDK.
Create shareable visualization applications inside Latch Pods.
Within the provider’s Latch workspace, they can iterate on pipeline and application development internally and assemble an “analysis package” to send to customers.
Providers can also create customer workspaces, dispatch an analysis package (with portions from Latch Data, Workflows, Pods, and Registry), and ship it to a customer workspace in just a few clicks.
Like AWS, Latch is a usage-based platform, so as customers store data, run workflows, or use visualization applications, they show up as Latch credits (1 credit = $1). The kit provider has complete visibility into the number of credits incurred for every customer workspace via an Admin Dashboard. They can also quickly transfer credits to a customer. Monitoring credit usage yields valuable insights, helping quantify customer engagement, revealing which aspects of the analysis package are most beneficial, and spurring innovative business models to generate new revenue streams.
Additionally, providers can subscribe to alerts for failed customer workflows, enabling rapid response and proactive customer support.
From a customer of a kit/assay/solution provider point-of-view:
They log into a beautiful, easy-to-use platform with the kit provider’s branding.
They are welcomed with a workspace curated for their specific assays. They only see the test data and workflow that they need. Customers can run bioinformatics pipelines themselves or, with a simple click on Latch Pods, access interactive visualizations through an intuitive application.
The entire process, from raw data to final insights, is streamlined, empowering them to achieve results in just one day.

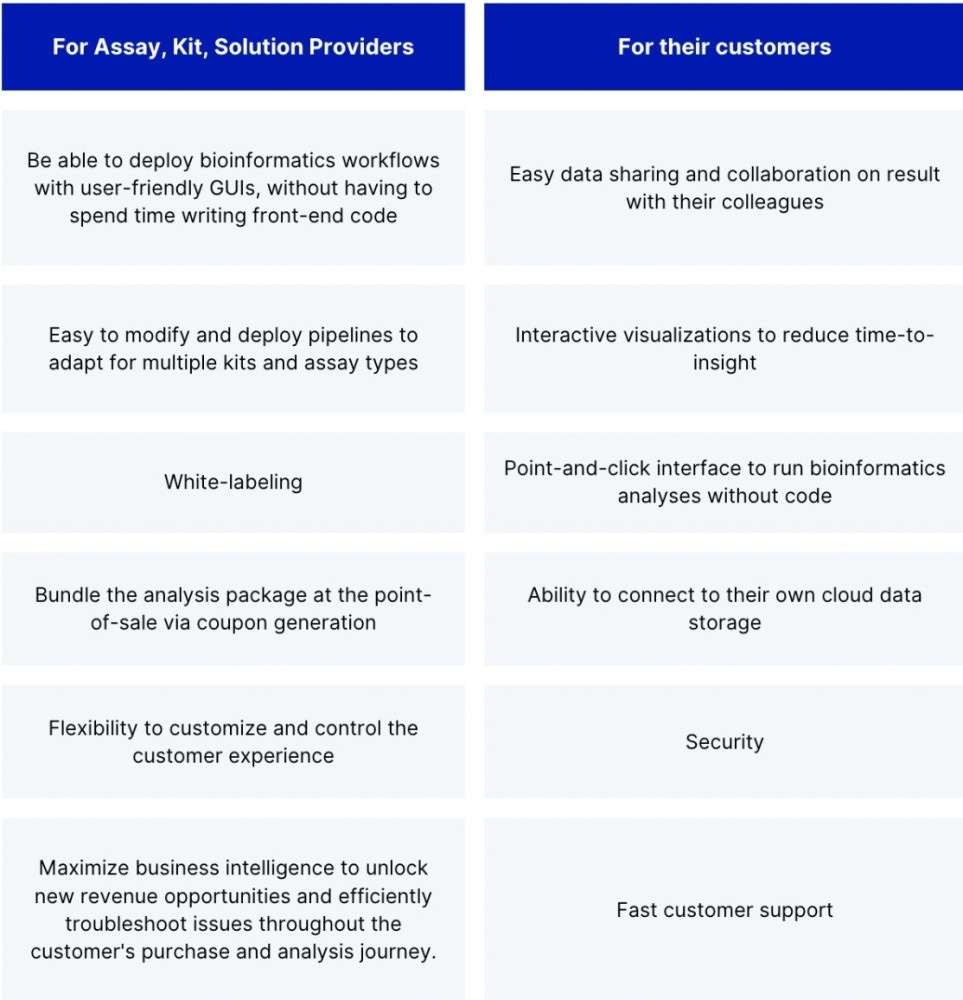
Key Benefits of a Bioinformatics Delivery Solution