


Weekly Tech+Bio News
ALSO: The rise of AI foundation models in biotech: a new paradigm

Hi! I am Andrii Buvailo, and this is my weekly newsletter, ‘Where Tech Meets Bio,’ where I talk about technologies, breakthroughs, and great companies moving the industry forward.
If you've received it, then you either subscribed or someone forwarded it to you. If the latter is the case, subscribe by pressing this button:
Now, let’s get to this week’s topics!

Weekly tech+bio highlights
Let’s have a look at some of the most important tech news in the pharma, biotech, and medtech spaces over the last couple of weeks:
🔬 Profluent introduces OpenCRISPR-1, an AI-designed, open-source gene editor freely available for ethical research and commercial use. This innovative tool, designed to edit human DNA with high precision and minimal off-target effects, marks a significant advancement in gene editing technology, potentially accelerating the development of new treatments for genetic disorders.
The 'ChatGPT for CRISPR' utilizes AI to innovate gene-editing tools, crafting systems potentially more adaptable than natural ones, and enabling precise genetic alterations with newly designed proteins and guide RNAs, as demonstrated in laboratory tests.
🚀 Xaira Therapeutics launches with over $1 billion in funding, spearheaded by Marc Tessier-Lavigne and supported by major venture capitalists. The new biotech startup aims to revolutionize drug R&D by leveraging AI to speed up drug discovery, with a focus on generating new proteins and running clinical trials.
(I wrote about this news in more detail in the last newsletter).
🔬 Lonza introduces its AI-enabled Route Scouting Service, designed to enhance synthetic route identification for complex small molecule APIs by integrating Lonza's chemical supply chain expertise with AI technology from Elsevier (Reaxys), aiming to optimize synthesis efficiency and supply chain resilience.
🔬 Boehringer Ingelheim partners with Ochre Bio in a deal worth over $1 billion to develop regenerative treatments for liver diseases, including late-stage metabolic dysfunction-associated steatohepatitis (MASH) cirrhosis. This collaboration aims to discover therapies that can reverse or slow disease progression in patients with advanced liver disease, focusing on RNA therapies and regenerative target validation.
🏛 The FDA approves Pfizer's Beqvez, its first gene therapy for adults with moderate to severe hemophilia B in the U.S., expected to transform patient care with its one-time $3.5 million treatment designed to enable patients to produce the blood clotting factor IX themselves.
🚀 Insilico Medicine relocates its headquarters from New York to Cambridge, Massachusetts, positioning itself in a biotech hub to enhance its AI-driven drug discovery operations. The move is part of Insilico's growth strategy, reflecting its progress in AI-generated drug development, including a Phase II clinical trial for an AI-discovered drug.
🔬 VantAI collaborates with Google Cloud to utilize NVIDIA H100 GPUs for advancing protein interaction predictions, aiming to increase the accuracy and speed of training all-atom protein interaction foundation models.
🔬 Deciphex collaborates with Novartis to develop AI-based tools for preclinical pathology assessments in drug discovery, aiming to enhance lesion detection across multiple species and secure regulatory acceptance.
🚀 Takeda, Astellas, and Sumitomo Mitsui Banking Corporation announce a joint venture to incubate early drug discovery programs, aiming to bridge the "valley of death" in drug development. Based in Shonan Health Innovation Park, Japan, this venture will focus on advancing innovative therapeutics from Japan to global markets, with an initial capital of approximately 600 million yen.
💰 Bristol Myers Squibb and Cellares announce a $380M global agreement to enhance the manufacture of CAR T cell therapies using Cellares’ automated Cell Shuttle platform. This collaboration aims to expand manufacturing capacity and improve the delivery of cell therapies to patients worldwide, leveraging facilities across the U.S., EU, and Japan.
💰 Rubedo Life Sciences secures $40M in Series A funding led by Khosla Ventures and Ahren Innovation Capital to advance clinical trials of its novel senolytic drug, RLS-1496, for treating chronic dermatological conditions like atopic dermatitis and psoriasis. This investment supports their ALEMBIC™ AI platform's development of therapies targeting senescent cells to potentially reverse age-related diseases.
🚀 Moonwalk Biosciences, newly launched, taps into epigenome editing with its innovative EpiRead and EpiWrite technologies, aiming to revert cells to healthier states by manipulating gene expression without altering the DNA sequence, demonstrating significant potential in precision medicine.
🔬 Scientists at UNC Chapel Hill have developed artificial cells with programmable peptide-DNA cytoskeletons, capable of dynamically changing shape and function, opening new possibilities for drug delivery, diagnostics, and regenerative medicine, as detailed in Nature Chemistry.
🔬 Valence Labs introduced MolGPS, a 1B parameter foundational model based on Graph Neural Network (GNN), designed for molecular property prediction, showcasing superior performance on multiple benchmarks like TDC, MoleculeNet, and Polaris.
Next, I’ve decided to republish part of my most read post in this newsletter, originally published in October 2023, and more relevant today than it was half a year ago:
AI Foundation Models in Biotech: New Paradigm
What are AI foundation models anyway, and why is there all the buzz lately? And most importantly, why should we care about this in the life sciences?
As you know, deep learning models have been trending ever since 2012, after a famous ImageNet competition where a deep convolutional neural network, AlexNet, achieved outstanding performance for image classification tasks, marking the beginning of the deep learning revolution in computer vision, with convolutional neural nets (CNNs) playing a key role.
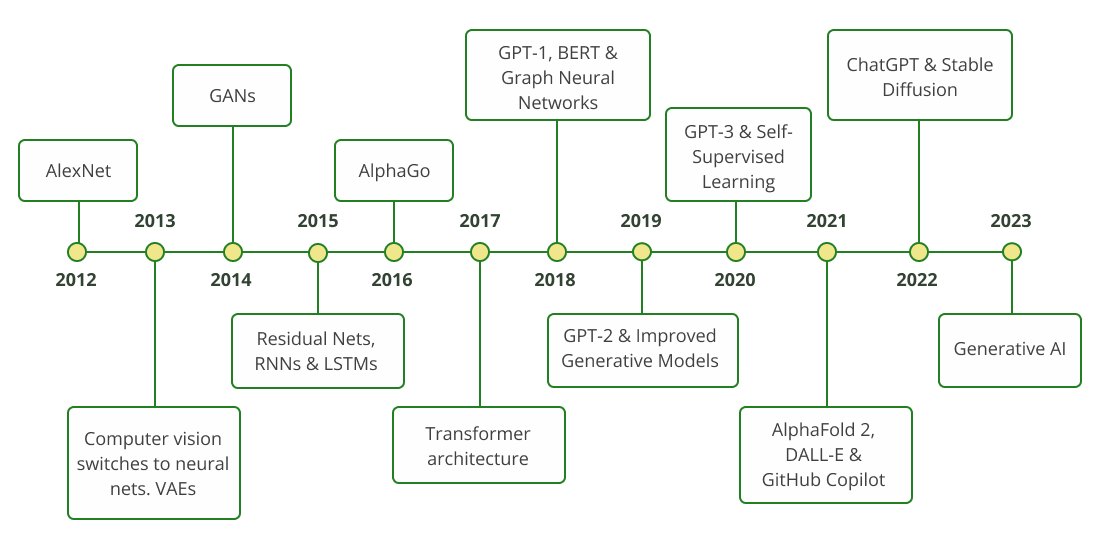
While CNNs are great for grid-like data structures, such as images and video frames, they are not good for sequential data, like time series. So, recurrent neural nets (RNNs) and LSTMs have joined the leaderboards of deep learning popularity quite soon, in particular in biology research.
CNNs, RNNs, and other deep learning architectures were quite popular in drug discovery, with lots of startups being founded during 2013–2017 exploiting the idea of AI-driven drug design. Some of these companies are now unicorns with AI-inspired molecules already in clinical development—Exscientia, Insilico Medicine, BenevolentAI, and Relay Tx, to name a few.
Notably, machine learning strategies of those years were primarily focused on supervised learning based on a properly laballed dataset, and datasets were relatively small (up to millions or hundreds of millions of parameters at best). Most importantly, the AI models of this period are specific to a certain narrow task. For instance, modeling target-ligand interaction or de-novo generation of small molecules biased towards desired properties, etc.
A really remarkable development occurred in 2017, a pivotal year for the AI field. Google engineers introduced a so-called transformer architecture for neural nets and a mathematical algorithm of attention in a seminal paper, ‘Attention is all you need.‘
This changed completely the playing field of deep learning and marked a paradigm-shifting rise of larger and more generalizable models. The most famous series of models includes the GPT-X family, with GPT-3 and GPT-4 being the foundations of ChatGPT, a recent phenomenon that I am sure you know well enough without my explanations.
What are foundation models?
A foundation model represents an AI neural network extensively trained on vast amounts of unprocessed data through unsupervised (self-supervised) learning, enabling its adaptability to a wide array of tasks.
Two key concepts underpin this overarching category: the simplification of data collection and the expansive range of opportunities it presents. Foundation models primarily learn from unlabeled datasets, eliminating the need for manual data labeling.
In contrast to earlier neural networks, which were narrowly specialized for specific tasks, foundation models can easily transition to various roles with minor adjustments, from text translation to medical image analysis.
Finally, foundation models can be fine-tuned towards domain-specific tasks, like chemistry, biology, mathematics, and so on. This is done by additional training of a foundation model, pre-trained on non-domain-specific data, on a domain-specific dataset.
Now, a crucial aspect of what makes foundation models so unique and different from previous eras of AI is the concept of ‘emergent abilities’. With the increasing number of parameters for training, the models start spontaneously acquiring novel and expanding capacities in various areas—pretty much like a child who first learns many different patterns and then suddenly gets visibly better at everything at once.
Understandably, emergent abilities may give rise to unexpected and very valuable properties of foundation models trained on biology data, which is already being proved experimentally by such companies as Recursion Pharmaceuticals.
The great filter
With all the paradigm-shifting promise of foundation models in drug discovery and biotech, it seems like this technology is further increasing the market entry barrier for new life science startups. In order to achieve technological advantage, you may need to build foundation models for your R&D task, but in order to build a domain-specific foundation model, you need a lot of domain-specific data in a certain area. This is a real challenge for the overwhelming majority of companies, except for several of those possessing unique experimental data generation capabilities, such as high-throughput experimentation facilities.
As Chris Gibson, co-founder and CEO at Recursion Pharmaceuticals, writes in his LinkedIn post:
‘To build broad foundational models in biology, you are going to need a lot of high-quality data. Aside from a few problems (e.g., protein folding), that data doesn't currently exist in the public domain. The winners of TechBio will have access to high-quality talent, deep compute resources, AND the ability to iteratively generate rich biological data at scale...
One day we will move wet-lab biology to confirmation and validation of in silico hypotheses only, but only those who can generate data at scale and quality today will get to that point for most drug discovery and development problems...’
There are several companies that possess unique data generation abilities via in-house resources. Let’s review how they are building foundation models and what they are planning to do with them.